In a decidedly “whoops” moment for Google, the latest image app Google Photos which (mostly) tags images with names of the objects in the photos, mislabelled a picture of two black people as “Gorillas”.
Not Google’s finest hour.
With the company admitting its new image recognition technology has flaws.
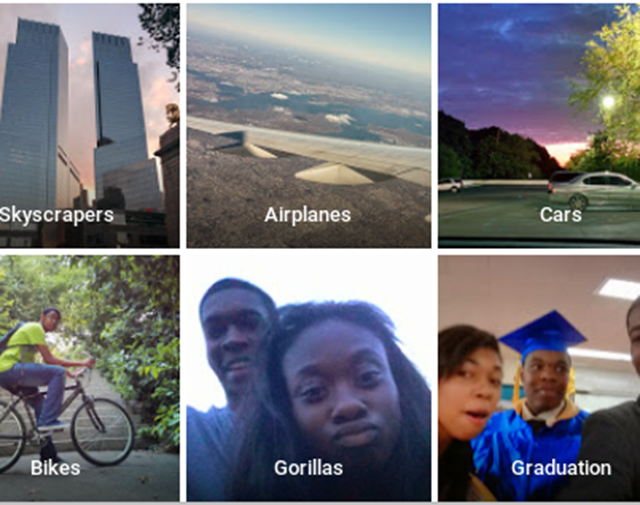 Image Credit: Jacky Alciné
Image Credit: Jacky Alciné
With his interests in equal rights, after seeing the image, Jacky Alciné of Brooklyn, New York, USA, tweeted:
“Google Photos, y’all f****d up. My friend’s not a gorilla.”
Yonatan Zunger, Chief Architect of Social at Google, responded with tweets of apologies and that there were problems with the technology. With the offending “Gorillas” tag likely caused by issues with obscured faces, skin tones and lighting.
Google subsequently formally apologised.
Google Photos has since removed the “gorilla” tag from its system.
Microsoft got into a similar problem many years back when it labelled one of its clip art images as “ape”. Not so much because of the gorilla as the main object and subject of the image, but because there was a black person in the background.
Calls of racism ensued; much like now with Google Photos.
The difficultly with such image recognition algorithms, is they do not function like human eyes and the human brain.
Subject to the algorithm construction, they are usually engaging in pattern searches, with fuzzy logic and proximal mapping (typically of pixels) often used, where the image may not be recognised exactly, but rather on what appears to be the most probable answer.
However, as this is often based on machine learning and past data, the tag given to an image could be very wrong because the algorithm has not ‘learnt’ things correctly subject to the data inputs and also because of the apparent probability of an outcome.
A grossly simplified, and purely speculative version of where Google Photos went wrong may have been as follows in the pseudo-algorithm:
Dark pixels
Oval shape
Facial features identified.
Probability of human? 10 percent.
Probability of gorilla? 90 percent.
Conclusion: Gorilla
Not that it makes it right – literally or socially – but the data inputted matters significantly.
As such, an algorithm may well struggle with anything which is in the minority with respect to the number of times that particular input has been represented in the past data relative to other inputs.
Whether that amounts to racism is open to debate; yet it may suggest that the humans programming and creating such algorithms need to be (more) cautious.
Despite the name “machine learning” the machine is not learning in the human sense.
Unlike humans, an algorithm lacks curiosity, and is therefore subject to being lacking in understanding and context.
Although understanding and context can be a tricky thing, even for humans.
Try answering the uthinki question by pressing the green button below. Where you’ll first answer what you think, then you’ll have to guess what others think is the answer and then indicate how confident you are with your guess.
As might be found, your own personal viewpoint may, or may not, be the same as that of other people.
If it’s challenging enough for us humans, now try explaining that to a machine.